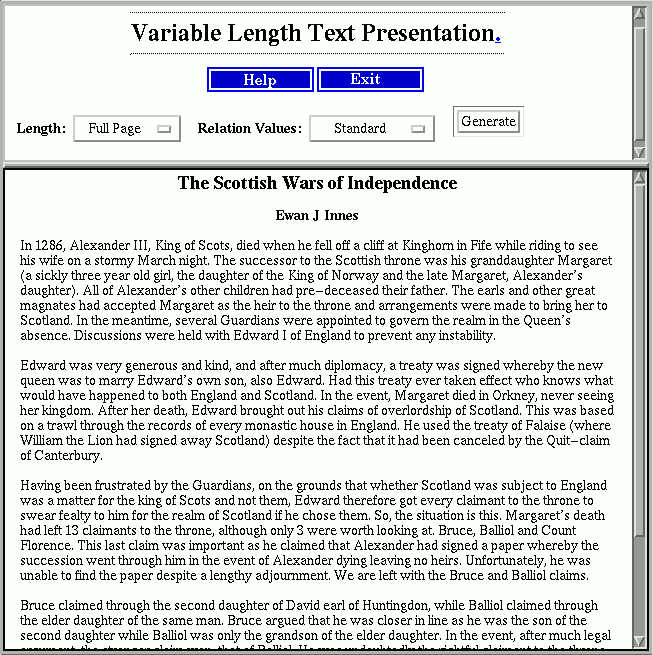
Figure 1: The VLDP interface
Mick O'Donnell
Department of Artificial Intelligence
University of Edinburgh
micko@aisb.ed.ac.uk
(For .ps file click here)
The value of such a technique is obvious -- some users want more detail and explanation, while others want or need less. A static hypertext document can only offer one level of detail. A variable-length document allows the user to choose their level of verbosity (see http://toros.ces.cwru.edu/veli/papers.html for work by Veli J. Hakkoymaz, applying this idea to multimedia presentations).
However, VLDs have not been practical given the current level of technology. Some approaches (e.g., Rino & Scott 1996) have discussed document summarisation on the basis of full natural language generation (NLG). However, the cost of authoring knowledge to support fully-generated documents has prohibited this approach, even if we allow that NLG has reached the required degree of robustness. Ono et al (1994) proposes building VLDs on the basis of automatic document structure recognition. However, I am yet to be convinced that such recognition is reliable on free text as yet.
This paper proposes an alternative technique for establishing VLDs, which substantially reduces the effort needed to get such documents on-line. Our technique involves the marking up of an existing natural language document using a document mark-up tool which we have developed, called the RST-Tool (see O'Donnell 1997b). The mark-up of the document is used to determine optimal locations for pruning of the text. Documents so marked-up can then be used for variable-length presentation, on the web or in some other hypertext environment.
Document mark-up involves indicating the rhetorical structure of the text, in terms of Rhetorical Structure Theory (RST -- Mann & Thompson 1987). RST structures a text in terms of a dependency structure, showing the rhetorical dependence between units of text. For instance, the first sentence of this paper is dependent on the second sentence, and stands in the relationship of BACKGROUND. The head of the dependency relation is called the nucleus, while the dependent text is called the satellite.
A common hypothesis about RST is that satellites are less essential to the text's goals than the nuclei. Thus, to produce a document of a particular length, we need only prune off branches of the RST tree until the required word limit is reached. The method of pruning is described in section 2. (Ono et al (1994) also prunes RST structures to achieve text summarisation. See O'Donnell (1997a) for a comparison of the two approaches).
Strictly speaking, hypertext involves text which can be clicked upon to reach some other body of related text. The technique described here does not so much apply to hyperlinking, but to the content of the nodes which are linked. Applying the technique to a hypertext document would change the contents (length) of each node in the document. A future development of the system will allow the user to zoom in on text by clicking on it: as a result of clicking on sentence punctuation, the full text dependent on that sentence will be presented. The work reported here has been carried out as part of the ILEX project, whose goal is to produce dynamically generated descriptions of objects in museums. See Knott et al (1996) for details.
The marked-up document is structured as a dependency tree, with each node of the tree being a segment of text. Each branch of the tree represents the relationship between a node (a nucleus) and an item of text whose occurrence is dependent on that text (the satellite). Figure 3 show the dependency analysis of a single sentence of the text. Note that while RST usually does not deal with dependency within the clause, for this application I provided a set of intra-clausal relations. Pruning of clausal adjuncts is an important source of summarisation without meaning-loss. The mark-up tool also allows the inclusion of multinuclear structures (a node whose children are text nodes of equal status, e.g., Sequence, Joint), and schemas, what are sometimes called ``story grammars'' allowing a sequence of named elements of structure, e.g., INTRODUCTION, BODY, CONCLUSIONS, BIBLIOGRAPHY, etc. Both of these structures are handled similarly to RST structures, so will not be discussed further.

This is a simple mechanism, but it has shown good results in producing reasonable texts at whatever degree of verbosity. There are however some cases where this method breaks down -- nuclearity does not always reflect centrality of information. Sometimes an author introduces information in a rhetorically unimportant place, yet that information may be needed later to understand the argument. One example of this in the summary shown earlier is where the original text had said: he was faced with constant pressure from Edward to sign. He refused to do so. In the summary, ``to sign'' was pruned, but it was actually a central concept, and the anaphoric ``so'' failed because of its pruning.
The text-nodes are then placed in a queue, position based on their relevance score.
Note that the satellites of a node will always have lower or equal relevance than the node itself, so we never include a satellite in the nodes-to-be-expressed list if its nucleus is not, which can produce incoherent text.
This paper has described a system for presenting variable-length on-line documentation, which allows the user to select the degree of verbosity of the text presented. The results so far on a small-scale have shown that reasonable-quality texts can be produced dynamically. The cost of document mark-up stops this approach being used on texts of short display-life, but makes it economical for documents of longer duration where length-variability has value.
Apart from text-length, VLDs allow the user a small degree of content-control, in that the user can determine the relevance of each RST relation (or of elements of a schema).
The major problem for the system involves restoring coherence after text-pruning, particularly in areas of reference, discourse markers, paragraphing and punctuation. The problems of paragraphing and punctuation have been solved, and solutions are suggested for the other two areas.
Regardless of the problems of this approach, the system is up and running on-line. New documents are being added as time allows, to test the generalisability of the approach.
O'Donnell, Michael 1997a ``Variable-Length On-Line Document Generation". Proceedings of the 6th European Workshop on Natural Language Generation. March 24 - 26, 1997 Gerhard-Mercator University, Duisburg, Germany.
O'Donnell, Michael. 1997b. ``RST-Tool: An RST Analysis Tool". Proceedings of the 6th European Workshop on Natural Language Generation, March 24 - 26, 1997, Gerhard-Mercator University, Duisburg, Germany.
Ono, Kenji, Kazuo Sumita, & Seiji Miike. 1994. ``Abstract generation based on rhetorical structure extraction''. Proceedings of the 15th International Conference on Computational Linguistics (COLING-94), Vol. 1. August 5-9, Kyoto, Japan.
Rino, L.H.M. & Scott, D.R. 1996. ``A Discourse Model for Gist Preservation''. In Dibio L. Borges and Celso A.A. Kaestner (eds.), Advances in Artificial Intelligence (Proceedings of the 13th Brazilian Symposium on Artificial Intelligence), pp. 131-140. Springer-Verlag, Germany.
Sparck Jones, Karen. 1993. ``What might be in a summary?", Information Retrieval 93: Von der Modellierung zur Anwendung (Ed. Knorz, Krause and Womser-Hacker), Konstanz: Universitatsverlag Konstanz), 9-26.